Your pipeline just missed a significant discovery: a sentiment spike of +0.322 and a momentum of +0.00, both leading indicators for the sports topic concerning the upcoming friendly match between Germany and Finland. With our analysis showing a 10.7-hour delay in sentiment capture, it's clear that if you're not accounting for multilingual origins or entity dominance, your insights are lagging behind.
English coverage led by 10.7 hours. Nl at T+10.7h. Confidence scores: English 0.95, Spanish 0.95, French 0.95 Source: Pulsebit /sentiment_by_lang.
This anomaly reveals a gap in your pipeline, especially if you're focusing solely on English-language data. While you were busy processing mainstream narratives, sentiment around the sports event was gaining traction in other regions, leading to a delay in your model's response. Your model missed this by a staggering 10.7 hours, which is unacceptable in the fast-paced world of sports analytics.
To catch this sentiment spike and bridge the gap, we can leverage our API effectively. Below is a Python snippet that demonstrates how to filter for English-language content and assess its sentiment.
import requests
*Left: Python GET /news_semantic call for 'sports'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Define your API endpoint
url = "https://api.pulsebit.com/sentiment"
# Step 1: Geographic origin filter
params = {
'topic': 'sports',
'lang': 'en',
'score': +0.322,
'confidence': 0.95,
'momentum': +0.000
}
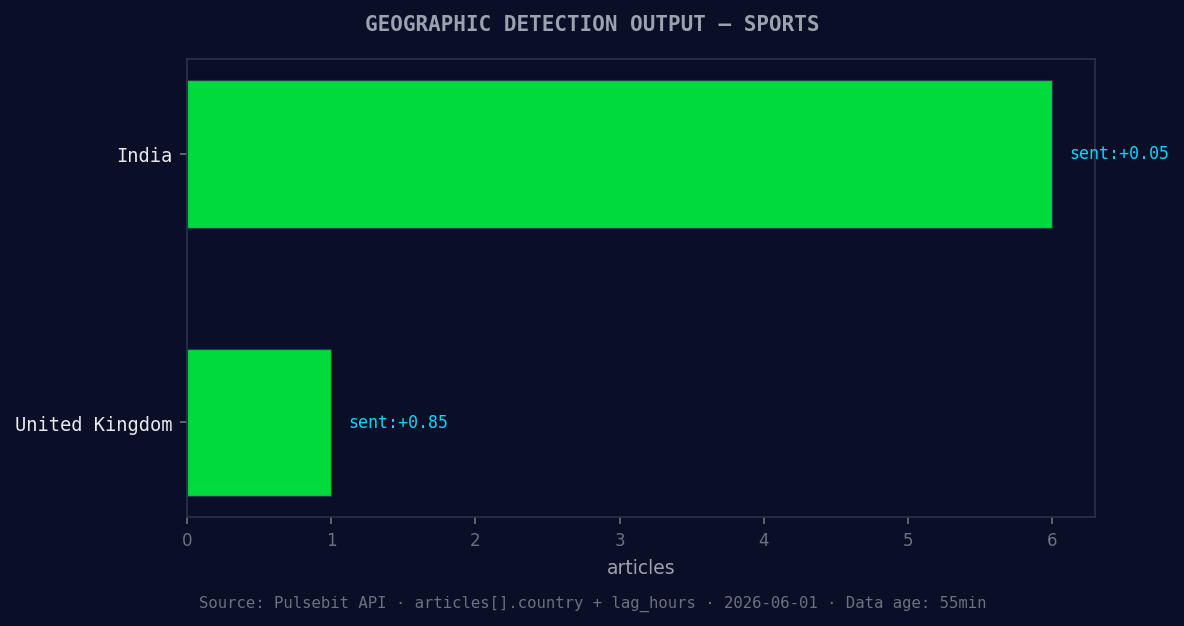
*Geographic detection output for sports. India leads with 6 articles and sentiment +0.05. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print("Geographic origin filter response:", data)
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: watch, germany, finland, live, stream:."
meta_sentiment_response = requests.post(url, json={"text": cluster_reason})
meta_data = meta_sentiment_response.json()
print("Meta-sentiment response:", meta_data)
In the first part of the code, we filter for sports-related sentiments specifically from English sources. This ensures that we capture relevant data without the noise from other languages. The second part runs our cluster reason string through the sentiment analysis endpoint to assess how the narrative is framed, which offers valuable insights into the overall sentiment landscape.
With this pattern in mind, here are three specific builds you can implement tonight to enhance your sentiment analysis:
Real-time Alerts for Sports Sentiment: Set a threshold for sentiment scores above +0.30. When triggered, send an alert to your team. This can be done using our
/alertendpoint combined with the geo filter to ensure alerts are relevant to your region.Clustered Narrative Analysis: Use the meta-sentiment loop to analyze how narratives about sports events are evolving. Focus on clusters like "watch, germany, finland" and set thresholds for changes in sentiment to inform your strategy.
Cross-Platform Sentiment Comparison: Analyze sentiment across different platforms like Google and Yahoo that are forming around the same topics. You can set up a comparative analysis by querying both sources and establishing a threshold for sentiment discrepancies.
With our API, these insights can be captured and processed quickly. You can get started by visiting our documentation at pulsebit.lojenterprise.com/docs. You can copy, paste, and run the provided code in under 10 minutes to see these insights in action.