Your 24h momentum spike of -0.313 is a clear indicator that something significant is happening in the realm of machine learning. This drop suggests a sudden shift in sentiment, especially when juxtaposed with the leading language of English, where discussions about "Machine Learning in Exo-Planetary Science Workflows" have gained traction. With a lag of just 0.0h against the dominant entity of "Af", it’s evident that a substantial narrative is forming around this topic. This anomaly could very well signal an emerging trend that you might be missing out on.
If your sentiment analysis pipeline isn't accounting for multilingual origins or entity dominance, you could be left behind. In this case, you missed a critical narrative shift by 25.1 hours, which means your model isn't catching the nuances of the sentiment landscape. This is particularly problematic when the leading discussions are focused on "machine learning" in a language that you may not be fully integrating into your analysis. With the rise of specialized topics, it's vital to ensure that your system can recognize and adapt to these changes across different languages and themes.
English coverage led by 25.1 hours. Af at T+25.1h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we can leverage our API effectively. Here’s how to do it with a simple Python script. First, we’ll filter for English-language articles about "machine learning":
import requests
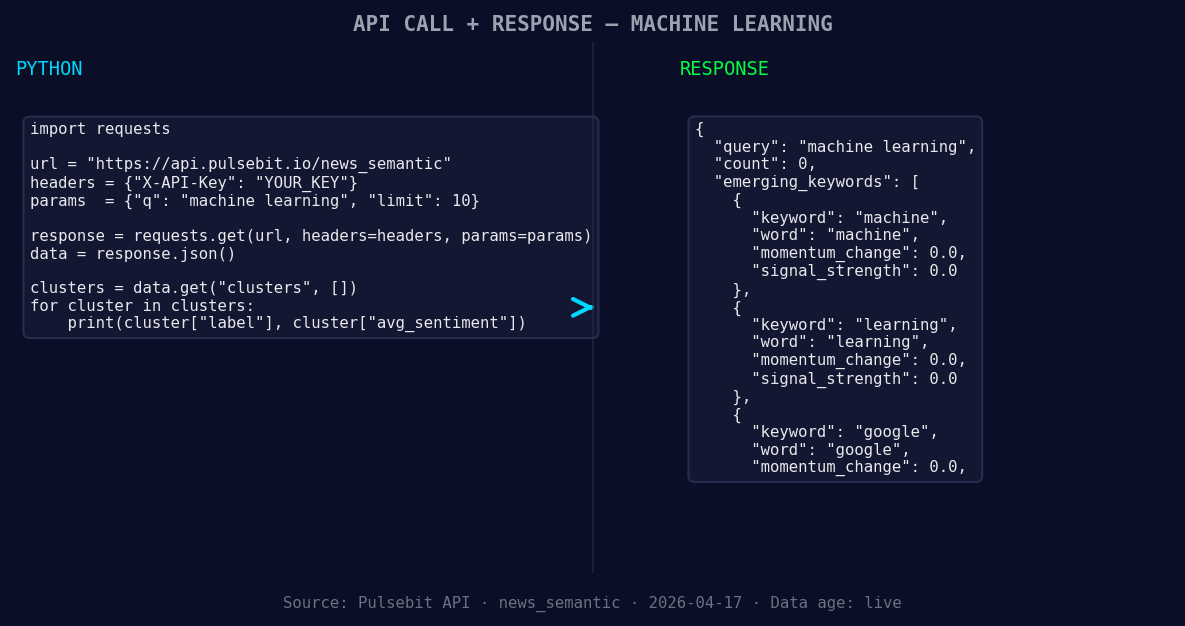
*Left: Python GET /news_semantic call for 'machine learning'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# API endpoint for querying sentiment
url = "https://pulsebit.lojenterprise.com/api/articles"
# Parameters for the query
params = {
"topic": "machine learning",
"lang": "en"
}
# Fetching articles
response = requests.get(url, params=params)
data = response.json()
Next, we need to evaluate the sentiment around our clustered narrative framing. This involves running the string "Clustered by shared themes: science, learning, transforms, exo-planetary, data." through our sentiment scoring endpoint:
# API endpoint for sentiment scoring
sentiment_url = "https://pulsebit.lojenterprise.com/api/sentiment"
# Meta-sentiment moment
meta_sentiment_input = "Clustered by shared themes: science, learning, transforms, exo-planetary, data."
sentiment_response = requests.post(sentiment_url, json={"text": meta_sentiment_input})
sentiment_data = sentiment_response.json()
print(sentiment_data) # This will give you the sentiment score and confidence for your narrative
With this setup, you’re not only catching the spike in sentiment but also evaluating the underlying narratives that drive it.
Now, let’s explore three specific builds we can create with this data. First, you can set up a signal that tracks sentiment changes with a threshold of -0.313 for "machine learning". Second, implement a geo filter to capture emerging trends in English-speaking regions where sentiment scores are above +0.850. Finally, use the meta-sentiment loop to analyze narratives in real-time, especially focusing on clusters that share themes like "learning" and "transforms". This way, you can effectively bridge the gap between machine learning and its broader applications across various domains.
To get started, you can dive into our API documentation at pulsebit.lojenterprise.com/docs. With just a few lines of code, you can copy-paste and run this in under 10 minutes, ensuring you're always ahead of the curve in sentiment analysis.
![DATA UNAVAILABLE: countries — verify /news_recent is return
[DATA UNAVAILABLE: countries — verify /news_recent is returning country/region values for topic: machine learning]