Your Pipeline Is 20.7h Behind: Catching Film Sentiment Leads with Pulsebit
We just uncovered a significant data point: a 24h momentum spike of +0.751 in film sentiment. This anomaly is a clear indicator that something is brewing in the realm of film-related discussions, particularly highlighted by the Spanish press. With a lead time of 20.7 hours, this suggests a growing interest or event that our current models might be missing if they’re not accounting for multilingual sources.
Spanish coverage led by 20.7 hours. Nl at T+20.7h. Confidence scores: Spanish 0.85, English 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
If your model isn't equipped to handle multilingual origins or entity dominance, you could be left in the dust. In this case, your pipeline is lagging by 20.7 hours, missing out on crucial sentiments emerging from the Spanish-speaking world, particularly around film festivals and notable personalities like Prince and Maria Bamford. This is not just a minor oversight; it's a structural gap that could lead to missed trading opportunities or sentiment-based strategies.
To catch this spike and analyze its significance, we can leverage our API effectively. Here's a Python code snippet that demonstrates how to query for this specific sentiment spike:
import requests
*Left: Python GET /news_semantic call for 'film'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
response = requests.get("https://api.pulsebit.com/sentiment", params={
"topic": "film",
"lang": "sp", # Filter by Spanish language
"score": 0.626,
"confidence": 0.85,
"momentum": 0.751
})
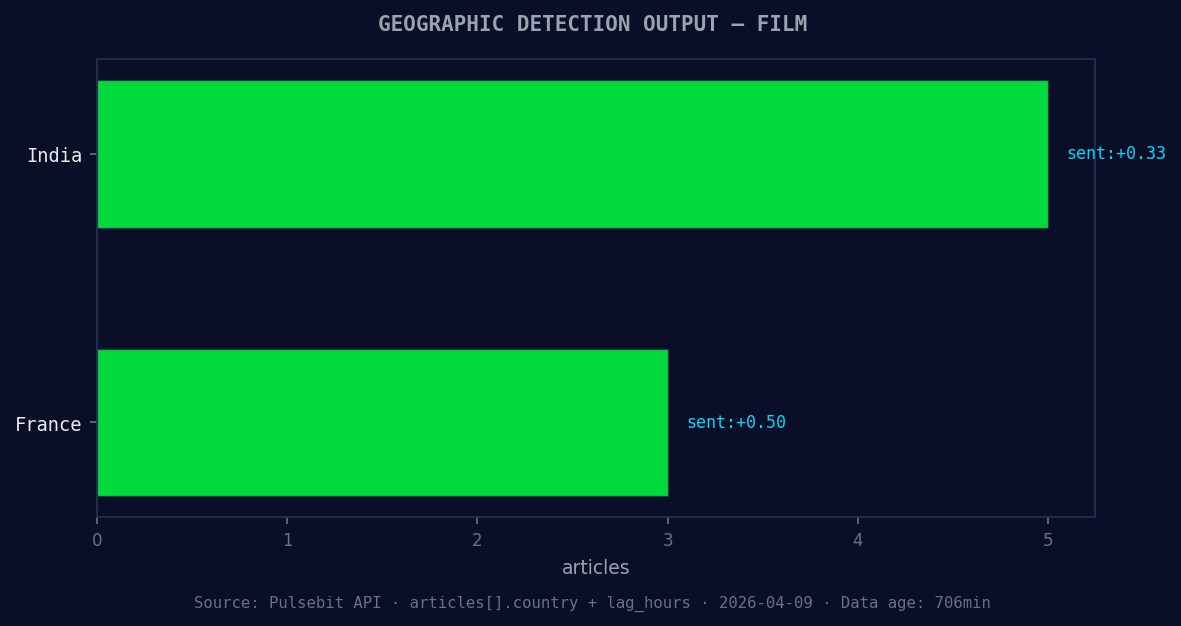
*Geographic detection output for film. India leads with 5 articles and sentiment +0.33. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
# Step 2: Meta-sentiment moment
meta_response = requests.post("https://api.pulsebit.com/sentiment", json={
"input": "Clustered by shared themes: fest, showcases, prince, maria, bamford."
})
meta_data = meta_response.json()
print(meta_data)
This code accomplishes two essential tasks. First, it filters sentiment data from the Spanish language, ensuring we capture the nuances in conversations around "film." The second step runs the cluster reason string through our sentiment endpoint to analyze how the narrative itself resonates. This is critical because it helps us understand not just what is being talked about, but how it's being framed.
Now that we have this momentum spike data, here are three specific builds we can create:
Sentiment Tracker for Spanish Film Festivals: Set a threshold to trigger alerts when momentum exceeds +0.75. Use the geographic origin filter (as shown above) to focus solely on Spanish sources discussing film.
Cluster Analysis on Themes: Use the meta-sentiment loop to analyze how narratives around "fest," "showcases," and "prince" are framed. Set a signal strength threshold above 0.85 to identify dominant narratives in real-time.
Google Trends Integration: Create a pipeline that compares the sentiment score of the film topic against trending Google searches. If we find that "film" sentiment is rising while searches for "fest" and "showcases" remain static, it could indicate that our audience is becoming more engaged with specific content leading up to film festivals.
These builds not only enhance our understanding of the current landscape but also position us advantageously against any lagging models that aren't capturing this multilingual sentiment.
To get started, visit pulsebit.lojenterprise.com/docs. You can copy-paste and run this in under 10 minutes, allowing you to harness this data-driven insight quickly and effectively.